Recommendation systems are a great revenue driver, but are tricky to implement for iGaming. Here's a hands-on method for implementing recommendations for games or events, that you can start using today
Recommendation systems are well known in the e-commerce industry, making the line “Customers who bought this item also bought” very famous. While names like Amazon, Booking.com and TripAdvisor jump to mind, recommendation systems are widely used in varied industries – movies (IMDB), music (iTunes/Google play) and even iGaming. Recommendations systems increase revenue through relevancy, improving the general customer experience, and cross/up sell.
Collaborative Filtering
Recommendation systems is a wide and complex area of research, occupying brilliant minds across the world. One of the most common approaches, which we will outline here, is collaborative filtering.
Collaborative filtering assumes that a customer will probably purchase
(or subscribe, hear, play etc.) in a similar way to other customers like him/her. To use this approach, data must be collected about customers’ consumption behavior.
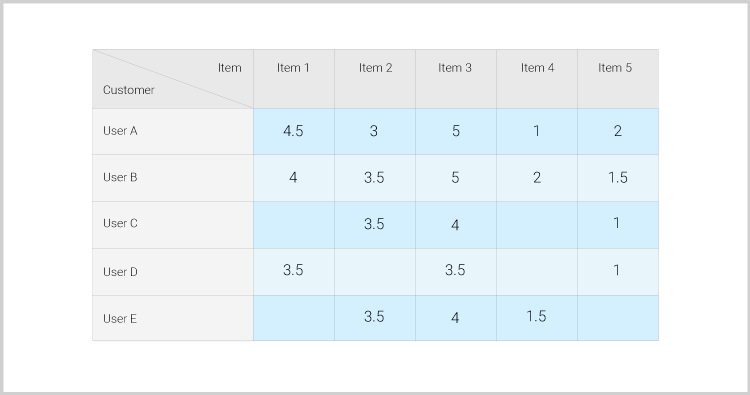
Below is the most basic matrix of collaborative filtering. The matrix can contain data on all your customers, or on a smaller and more granular segment (i.e. Active users). It has two dimensions – customers (Rows), and Items (columns). The items can be any product or service you can recommend to your customers. The rating inside the matrix (between 1 to 5) represent the customers’ rankings for a specific item. The ranking can be derived from explicit data (rankings, reviews, likes etc.) and implicit data (which items the user has looked for, which items were bought, demographic attributes etc.).
Eventually, the following matrix should be computed:
(Empty cells denote unranked items.)
After computing the matrix, we can use the existing information to conduct the following steps:
Identify similar users (“neighbors”). One of the common methods for calculating the similarity between users is the Pearson correlation.
Predict the rating for an item, based on similar users. Grouping similar users can be done using the KNN (K – Nearest Neighbors) algorithm.
In our example, usersA, BandC are similar in terms of ratings for items2, 3and5, so we can call them neighbors. Users AandB gave an average ranking of 4.25 to item 1 and 1.5 to item 4. So, if we need to choose one item to recommend to user C, it will be item 1.
There are two ways which collaborative filtering can be used:
User-User (row dimension): this method will answer the question which item should I recommend to user A? (The missing ranking will be derived by looking at the rows, like in the example above.)
Item-Item (columns dimension): this method will answer the question to which users should I recommend Item X? (The missing ranking will be derived by looking at the columns.)
Why is iGaming Different?
Before answering this question, let’s review a list of possible inputs for our recommendation system:
Demographic attributes – age, gender, country, single/married etc.
Purchase history – which items did the customer buy? Which items are in his Wishlist? Which items has the customer browsed?
User ranking – a specific rank for a product.
User reviews – “I highly recommend buying this product”.
Likes/Dislikes – adds on Facebook, songs in iTunes.
Most of these inputs cannot be used in the iGaming industry, simply because most iGaming companies don’t have this data, and the same goes for both casino and social casino.
Obviously, iGaming requires a different approach. In iGaming, the two most important features that imply player preference are bet amount and number of bets. In addition, we can also consider the frequency for a specific game/event, or total session time (more relevant for social gaming). For example, in the past 6 months, a player played game A 300 times, game B 200 times and game C 20 times. If you want to be more sophisticated, you can combine two or more of these attributes. This information can help us understand which games the player liked more than others. To get reliable results, it’s crucial to normalize metrics for the different products. For instance, for bet amount $50 in sport should be treated differently from $50 in the casino, due to the different nature of the games and the different margins between the products.
Do It Yourself
Congratulations, you’ve made it to the best part! In the next section, we will guide you with simple and easy way to implement a recommendation system for your customers.
Step 1 – Choose your sample Collaborative filtering suffers from 3 main problems – cold start (we have no information on new players), scalability (the user item matrix is enormous), and sparsity (many missing rankings). to address these issues, we will segment only active players who experienced several different games/events, and that make most of their bets in a specific product (e.g. casino, sport, Lottery etc.).
Step 2 – Calculate favorite game/event Using the attributes we mentioned earlier, the favorite game/event will be calculated for each player.
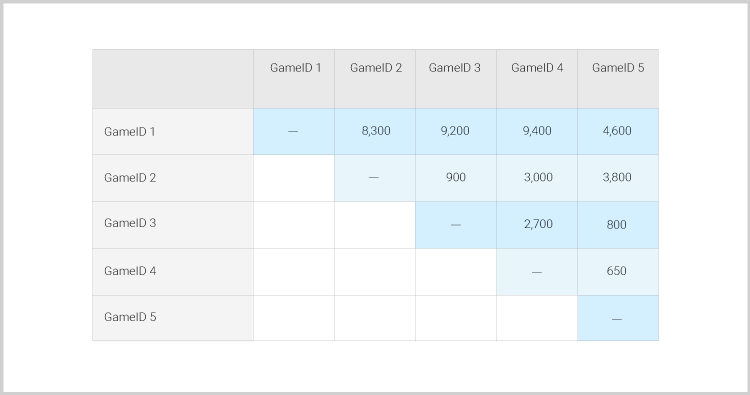
Step 3 – Compute co-occurrence matrix A co-occurrence matrix is very similar to the user-item matrix, but it has only one dimension. It looks like this:
The matrix values reflect the number of customers who played two specific games. For example, 8,300 players played both gameID 1 and gameID 2. This table gives us the first intuition about which two games are associated. If you are familiar with association rules, you know that the percent of players who played each game has a high impact on the results. For example, what if a company gives all free bets only on gameID 1? Or what if a specific game is displayed in the center of the company’s homepage, so almost every new player tries it? This type of cases can skew our results. Therefore, we will use the Jaccard Similarity to normalize the matrix. The process is very simple – each number in the matrix will be divided by the sum of players who played each game.
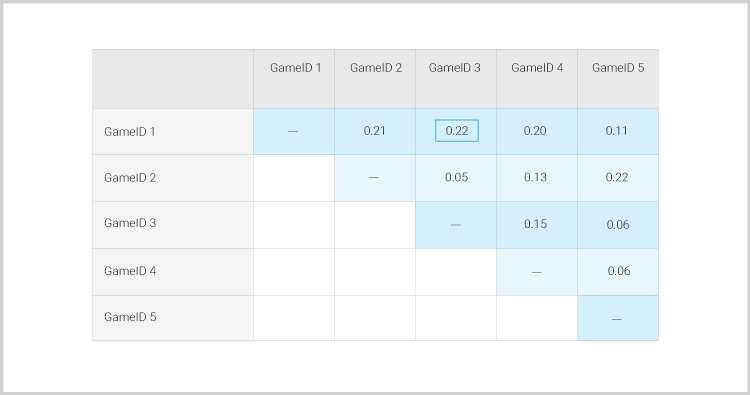
This is the normalized matrix:
The marked value was calculated as follows:
It’s interesting to see that despite more players having played games 1 and 4, the highest score in the normalized matrix is for games 1 and 3.
Below is a short MsSQL code for creating a co-occurrence matrix:
Games table – transactional table that holds all gaming activity
ActiveCasinoPlayers table – the population you want to build the system for
The output will be the number of players who played both games for each gameID combination (Number_of_Occurrences field).
Step 4 – Create recommendations Based on each player’s favorite game, you can now use the co-occurrence matrix to find the best match. For example, if a player’s favorite game is gameID 2, we will recommend gameID 5 since it holds the highest score – 0.22. Of course, this can be further developed by choosing the top 3 games we should recommend depending on tactical or strategic goals (pushing a stumbling game, cross selling to high margin games etc.)
Step 5 – Additional dimensions This step is optional, and its main purpose is to show you that there are endless options in designing the system. Let’s say that we want to recommend gameID 5 to all players whose favorite game is gameID 2. What if some of those players already play gameID 5? To avoid redundant recommendations, we can create vectors for each user that show how many times he/she played each game. Based on this vector, we can create a second normalization by dividing the Jaccard similarity score by the number of times the player has played the recommended game. The more a player played the game, the lower the score the game gets. This way, games that the player hasn’t played before will rise to the top.
There may be other parameters that you’d want to consider, for example seasonality in sports, game platform (a game might be very popular on mobile, but less so on the web) and side games in social casino.
Final Notes
This is only the tip of the iceberg of recommendation systems. If you’d like to take a stab at implementing one for your iGaming business, the 5 steps specified here will allow you to do so in a fast and simple way that could get you some quick wins with your cross selling. Happy recommendations!
Nimrod (Nimi) Ifrach, Director of Data Science at Optimove, leading all the onboarding and data integration processes in the North America market.
Nimrod has vast experience across different business verticals – retail, subscription, iGaming and more.
He delights in turning statistical power into business value, always keeping the data at the center. Nimrod holds a BSc in Industrial Engineering and Management from the Tel Aviv University.